

Wir erwarten von Datenträgern und Dateisystemen, dass diese unsere Daten sicher speichern. In der Praxis kommt es allerdings immer wieder zu unerwarteten und unentdeckten Datenverlusten. Wie kommt es dazu, und wie kann die Wahl des (richtigen) Dateisystems die Situation entschärfen?
Das Standard-Dateisystem für neue Linux-Installationen ist üblicherweise immer noch ext4. Es bietet erhebliche Vorteile gegenüber älteren Dateisystemen, insbesondere verhindert das eingebaute Journaling Datenverlust im Falle eines Stromausfalls oder falls das System unerwartet nicht mehr reagieren sollte. Aber ext4 fehlen immer noch viele Funktionen, welche man heute von einem modernen Dateisystem erwartet:
- Konsistenter Zugriff auf ältere Dateisystemzustände (Snapshots), z.B. zum Erstellen von Backups ohne das System anhalten zu müssen
- Mehr als eine Dateisystemhierarchie auf einem einzelnen Massenspeicher (Subvolumes). Partitionen werden dadurch überflüssig, und der Speicherplatz kann eventuell effizienter genutzt werden
- Online-Kompression
- Deduplikation (Datenblöcke mit demselben Inhalt werden nur einmal gespeichert)
- Zusätzliche Prüfsummen, um Datenverluste zu verhindern
- Stärkere Kopplung an das/die Speichersubsystem(e), damit Prüfsummen in Fehlersituationen zur besseren Entscheidungsfindung verwendet werden können
Die Erweiterung von ext4 um diese Funktionen würde wesentliche Änderungen am Programmcode und den Datenstrukturen auf der Festplatte (dem sogenannten Disk-Layout) erfordern. Außerdem wären Konvertierungsstrategien für ältere Laufwerke erforderlich, und die Benutzer könnten ihre neu formatierten Datenträger nicht mit älteren Systemen verwenden. Dateisystem-Entwickler versuchen dies bis zu einem gewissen Grad zu vermeiden, indem sie generische Datenstrukturen und Flags verwenden. Häufig kann man bei der Formatierung des Dateisystems entscheiden, welche Funktionen aktiviert werden sollen, und einige davon sogar erst später aktivieren oder auch wieder deaktivieren.
Snapshots, Subvolumes, Deduplikation oder Kompression interessieren mich nicht, aber Datensicherheit ist mir sehr wichtig. Ich möchte daher kein Dateisystem mehr verwenden müssen, welches keine Prüfsummen verwendet.
Warum sollte ich mich für Datensicherheit interessieren?
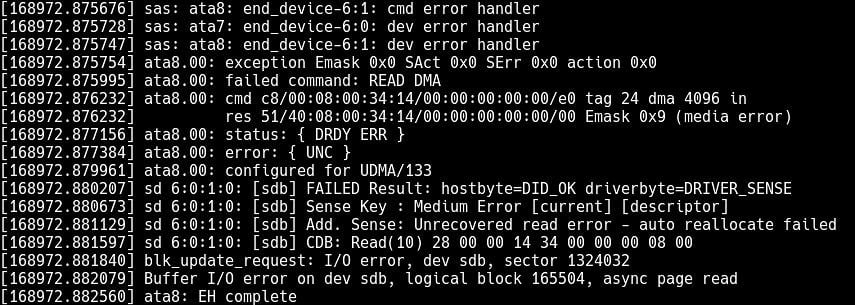
Daten werden auf Massenspeichern normalerweise in Blöcken (oder “Sektoren”, wie man diese in den 1980er Jahren nannte) gespeichert. Man erwartet vom Laufwerk, dass es dem Betriebssystem mitteilt, falls es einen dieser Blöcke nicht mehr lesen kann. Dies kann besonders bei magnetischen Laufwerken vorkommen. Manchmal sind die Magnetplatten zu alt und können nicht mehr ausreichend magnetisiert werden, um während der nächsten Lesephase die korrekten Signale zu erzeugen. Oder der Lesekopf ist nicht richtig positioniert und liest den falschen Sektor. Oder die kosmische Hintergrundstrahlung lässt ein Bit “umkippen”. Solid-State-Laufwerke (SSDs) leiden allerdings auch unter Verschleiß. Ab einem gewissen Punkt sind die Flash-Zellen nicht mehr in der Lage, ihre Ladung bis zum nächsten Lesezyklus zu halten. Programmierfehler in der Laufwerks- oder Controller-Firmware sind ebenfalls eine mögliche Fehlerquelle.
In der Praxis kann den Laufwerken und Controllern nicht vertraut werden, und die ursprüngliche Annahme erweist sich leider als unwahr. Ich habe viel zu viele Fälle gesehen, in welchen ein Laufwerk/Controller falsche Daten oder sogar bei jedem Zugriff auf denselben Sektor unterschiedliche Daten zurückgeliefert hat. Entweder wusste das Laufwerk nicht, dass die Daten unbrauchbar waren, weil es gar keine Möglichkeiten hatte, diese zu überprüfen. Oder die Firmware war eben fehlerhaft.
Laut einer alten Studie von DeepSpar, einem Dienstleister für Datenwiederherstellung, war menschliches Versagen in nur zwölf Prozent der analysierten Fälle die Ursache für den Datenverlust, Softwarefehler in dreizehn Prozent der Fälle, aber Laufwerksausfälle (38%) und Lesefehler (30%) machten den Löwenanteil aus. Dies passt sehr gut zu meiner eigenen Erfahrung.
Ich erwarte nicht, dass sich die Situation in Zukunft verbessern wird. Die Hardwarefehlerraten werden nicht wesentlich sinken, aber die Softwarefehler scheinen sich zu verschlimmern. Ich musste in meiner ganzen professionellen Karriere (mittlerweile immerhin über 20 Jahre) nie die Firmware einer Magnetfestplatte aktualisieren. Aber im Falle von SSDs ist dies so üblich geworden, dass es sogar Firmware-Update-Tools mit grafischen Oberflächen für normale Heimanwender gibt.
Man muss also davon ausgehen, dass ein Laufwerk irgendwann stillschweigend Daten verlieren wird, die technische Bezeichnung dafür ist Silent Data Corruption (“Stille Datenkorruption”). Das ist natürlich eine ziemlich schlechte Nachricht für uns alle. Die Laufwerke speichern immer mehr Daten, sind immer länger im Einsatz und die Migration der Daten auf ein neues Laufwerk dauert immer länger. Silent Data Corruption umgeht sogar Backup-Strategien, welche die Daten regelmäßig zu einem “zuverlässigen” Server oder Cloud-Provider übertragen. Wenn die Daten auf dem lokalen System beschädigt sind, wird das Backup irgendwann auch mit den fehlerhaften Daten überschrieben – was man dann erst herausfindet, wenn es zu spät ist.
Dies betrifft auch alle Datentransfers zwischen zwei Systemen, z.B. mit Hilfe von USB-Laufwerken. Die Daten, welche das erster Gerät auf dem Laufwerk speichert, sind möglicherweise nicht identisch mit den Daten, welche das zweite Gerät später lesen wird.
Selbst RAID hilft nicht
Die Nutzer erwarten, dass RAID-Arrays ihre Daten schützen, aber fast alle Implementierungen tun dies nicht. RAID 0 bietet sowieso keine Redundanz, falls eines der Laufwerke einen Block verliert, sind die Daten nicht mehr vorhanden. Aber auch die RAID-Level 1/5/6, welche Redundanz und/oder Paritäten zur Erhöhung der Datensicherheit verwenden, haben ein großes Problem: Die Entwickler opfern im Normalfall Datensicherheit zu Gunsten einer höheren Geschwindigkeit. Die redundanten Kopien oder die Paritäten werden dann nur überprüft, wenn ein Laufwerk einen Lesefehler gemeldet hat. Andernfalls wäre das gesamte Array – im besten Fall – nur so schnell wie ein einzelnes Laufwerk.
In den letzten zwanzig Jahren ist mir nur einen einziger Hardware-RAID-Controller untergekommen, welcher dazu gezwungen werden konnte, die Parität bei jedem einzelnen Lesevorgang zu überprüfen. Software-Implementierungen wie Linux md-raid und LVM können ebenfalls nicht dazu gezwungen werden. Alles, was man tun kann, ist regelmäßige Überprüfungen (“Scrubs”) des gesamten Arrays durchzuführen. Aber wenn die Daten zwischen zwei Scrubs stillschweigend verloren gegangen sind, hat man ja schon die ganze Zeit mit den fehlerhaften Daten gearbeitet. Herzlichen Glückwunsch.

Im Fall von RAID 1, welches einfach eine Kopie der Daten auf einem zweiten Laufwerk speichert, kommt es sogar noch schlimmer. Wenn man bei jedem Zugriff beide Kopien eines Datums lesen würde (was sowieso niemand tut), und sie wären nicht identisch, welcher der beiden könnte man dann vertrauen? Es gibt keine automatische Lösung für dieses Problem. Daher werfen die meisten Implementierungen (einschließlich das in Linux enthaltene Software-RAID md-raid) eine Münze und vertrauen dem beschädigten Block in 50% der Fälle. RAID 1 ist also ohne zusätzliche Vorsichtsmaßnahmen wertlos. Eine recht ironische Situation, da viele Heimanwender ihren RAID-1-NAS-Boxen mit zwei Laufwerken schließlich ihre Backups anvertrauen.
Wie Prüfsummen Daten schützen helfen
Die Standardlösung für all diese Probleme besteht darin, für jeden Datenblock eine Prüfsumme zu berechnen und diese zusätzlich separat zu speichern. Jedes Mal, wenn ein Block gelesen wird, überprüft der Dateisystemcode, ob die Prüfsumme immer noch mit den Daten übereinstimmt. Falls nicht, lügt das Laufwerk. Enterprise-Laufwerke können Prüfsummen in einem separaten Bereich speichern, indem sie im Hintergrund größere Blöcke mit einer Größe von 520/4104 statt 512/4096 Bytes verwenden.
Auf die zusätzlichen acht Bytes kann das Betriebssystem über eine Funktion namens T10 Protection Information (T10-PI) zugreifen. Auf Consumer-Laufwerken muss das Dateisystem die Prüfsummen zusammen mit dem Rest der Daten speichern, wodurch der dem Nutzer zur Verfügung stehende Speicherplatz leicht reduziert wird.

Dies ist in allen Situationen nützlich. Selbst wenn nur ein einziges Laufwerk verwendet wird, erfährt man sofort, falls dieses Daten verliert und kann dann Schlimmeres verhindern. Das Betriebssystem meldet dann Lesefehler an die Anwendungen, statt beschädigte Daten zurück zu liefern. Die Backup-Software überschreibt das gute Backup auf dem Server oder in der Cloud nicht. Man liest keine keine beschädigten Daten von einem billigen USB-Stick.
Prüfsummen lösen auch die meisten der erwähnten RAID-Probleme. In einem RAID 1 kann man nun plötzlich herausfinden, welches der beiden Laufwerke lügt, und dann der guten Kopie vertrauen. Man kann schnelle UND sichere RAID-5/6-Arrays bauen, da man jetzt bei jedem Lesezugriff mit Sicherheit feststellen kann, ob die Daten beschädigt wurden, und diese dann aus den Paritäten rekonstruieren kann. Man kann sogar versuchen, die beschädigten Daten mit der guten Kopie zu überschreiben (sogenanntes “Resilvering”). Oft wird das Laufwerk dann den Block neu zuordnen und muss nicht sofort ersetzt werden.
Warum ZFS oder BTRFS?
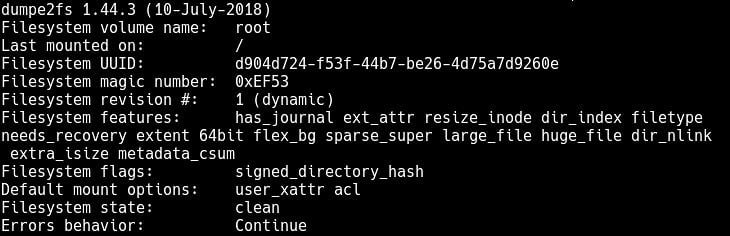
Von den gängigen Linux-Dateisystemen sollten ext4 und XFS um Prüfsummen sowohl für Metadaten als auch für Datenblöcke erweitert werden. Die xfsprogs aktivieren seit Version 3.2.3 (veröffentlicht im Mai 2015) ab Werk Metadaten-Prüfsummen für alle neu angelegten XFS-Dateisysteme. Die e2fsprogs aktivieren das Flag metadata_csums (Metadaten-Prüfsummen) erst seit der Version 1.44.0 (veröffentlicht im März 2018). Ältere Linux-Distributionen liefern in der Regel keine ausreichend aktuelle Version von e2fsprogs aus, so dass dieses Feature die meiste Zeit ungenutzt bleibt.
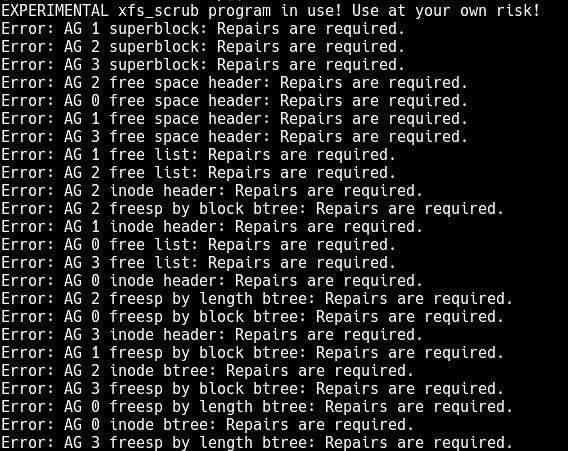
Der experimentelle xfs_scrub-Befehl kann eine Online-Überprüfung eines XFS-Dateisystems durchführen, für ext4 gibt es keine Online-Dateisystemüberprüfung.
Ext4 und die meisten anderen Linux-Dateisysteme sind auch nur sehr lose mit der Speicherschicht verbunden. Zum Beispiel interessiert es den Dateisystem-Code nicht, ob das Dateisystem auf einem RAID-Array, einer internen SSD oder einem USB-Stick läuft. Er sieht in allen Fällen nur einen einzelnen, großen, simplen Massenspeicher. Selbst wenn Prüfsummen vollständig hinzugefügt und aktiviert werden würden, könnten alle weiter oben genannten RAID-Tricks nicht realisiert werden. XFS und ext4 sind also trotz der existierenden Metadaten-Prüfsummen keine guten Lösungen für das Problem.
Sun Microsystems hat für Solaris das ursprünglich Zettabyte File System getaufte ZFS als modernes Dateisystem mit vielen Funktionen entwickelt, darunter Prüfsummen für alle Daten. Es verfügt über eine eigene Speicherschicht, eigene RAID-Implementierungen und kann alle Prüfungen online durchführen (also während das Dateisystem eingebunden ist). Es wurde als Teil von OpenSolaris unter einer Open-Source-Lizenz freigegeben, kann aber aufgrund von Lizenzbeschränkungen nicht einfach in den Linux-Kernel integriert werden. Ubuntu ist die einzige Linux-Distribution, welche ein vorgefertigtes ZFSonLinux-Kernel-Modul mitliefert. Unter allen anderen Distributionen ist die Installation komplizierter.
Ich empfehle die Verwendung von ZFS, sofern nichts dagegen spricht, benutze es selbst aber auch nur in meiner Ubuntu-basierten NAS und einigen anderen Servern. Die Einrichtung ist vergleichsweise kompliziert. ZFS wurde auch nicht für die Nutzung auf externen, entfernbaren Laufwerken (z.B. USB-Festplatten) ausgelegt, was es für viele Anwendungsfälle weniger attraktiv macht.
BTRFS bietet viele der von ZFS eingeführten Funktionen, einschließlich Prüfsummen und eigener RAID-Level-Implementierungen, ist aber Teil des Standard-Linux-Kernels und unter der GPL lizenziert. Es kann mit den meisten Linux-Installationen bereits seit vielen Jahren genutzt werden. Im Gegensatz zu ZFS unterstützt es externe Laufwerke, man kann diese sogar einfach wie gewohnt anschließen und mit der bevorzugten graphischen Oberfläche mounten. Leider hat BTRFS einige große Probleme mit möglichen Datenverlusten in den RAID5/6-Modi, daher sollten diese Modi nicht verwendet werden. Es ist immer ratsam, erst im BTRFS-Wiki zu überprüfen, ob der eigene Anwendungsfall vollständig unterstützt wird.
Ich verwende BTRSFS seit ca. zwei Jahren ohne Probleme im RAID 1- und RAID10-Modus für Scratch-Arrays und alle externen USB-Laufwerke. Meines Wissen ist Synology der einzige Hersteller, welches BTRFS auf seinen NAS-Systemen anbietet, ich habe die genaue Implementierung aber nicht überprüft.
Dieser Gastbeitrag wurde ursprünglich von Simon Raffeiner für lieberbiber.de verfasst und erschien dort auf Englisch unter dem Titel “Improving data safety on Linux systems using ZFS and BTRFS”.
Artikelbild von Patrick Lindenberg auf Unsplash




7 comments On Mehr Datensicherheit unter Linux dank ZFS und BTRFS
Hallo Simon,
ist BTRFS ein geeignetes Dateisystem für folgendes Speichermedium: SLC-Stick.
(SLC-Speicherzellen liegen zwischen 250.000 und 1.000.000 Schreibzyklen. Um die Lebensdauer nochmals zu erhöhen, verwenden Flash-Speicher Techniken um die Speicherzellen gleichmäßig abzunutzen, das sogenannte “Wear-Leveling”.)
Mit weiteren Massnahmen lässt sich das Logging auf dem Datenträger noch weiter reduzieren: ramlog for systemd (https://github.com/azlux/log2ram)
Gruß
Thomas
Hallo,
optimal wäre für solche Zwecke natürlich ein Dateisystem wie das Flash-Friendly File System (F2FS). Leider unterstützt dieses keine Checksums.
BTRFS schlägt sich auf SSDs zumindest nicht schlechter als ext4. Ab Werk werden bereits einige Optimierungen für SSDs automatisch aktiviert, falls BTRFS von einem Datenträger gemountet wird, welcher als nicht-rotierend erkannt wurde (/sys/block/*/queue/rotational liefert den Wert “0”). TRIM wird ebenfalls unterstützt. Meiner Erfahrung nach ist BTRFS sowieso sehr träge, was das Rückschreiben von Daten auf die SSD angeht, und puffert Daten erst mal lieber in den Arbeitsspeicher.
Für Systemplatten habe ich BTRFS bislang nicht im Einsatz, allerdings in mehreren SSD-RAIDs und auf externen Datenträgern. Über die System-Logs würde ich mir keine großen Sorgen machen. Zum einen scheinen diese mit ext4 ja auch keine Probleme zu verursachen, und zum anderen sind die Datenmengen recht klein. Ich schiebe seit zwei Jahren regelmäßig in einem Zug zwischen 50 und 150 GB auf ein BTRFS RAID1 aus normalen Consumer-SSDs und lösche die Daten dann wieder. Die Lebensdauer der Triple Level Cells der verwendeten Samsung EVO 850 wird mit 3.000 Schreibzyklen angegeben. Bislang meldet S.M.A.R.T. keine “reallocated sectors”. Eine SLC-SSD sollte also noch weniger Probleme damit haben.
viele Grüße,
Simon
Das beim RAID 1 eine Festplatte falsche Daten zurück liefern ist ein extrem seltenes Scenerario. In meiner Laufbahn als ITler habe ich das noch nie erlebt. Was sehr häufig vorkam, war, dass die Festplatte komplett ausgefallen war (Leseköpfe kaputt, das berühmte Rattern/Klacken). Und da hilft RAID 1 natürlich. Außerdem sollte erwähnt werden, dass BTRFS im Prinzip keine Zukunft mehr hat und die Community auf das nächste Pferd setzt, wie z.B. bcachefs.
Wir haben Silent Data Corruption schon mehrfach gesehen. Am Ende des Tages ist es aber im Prinzip egal, wie häufig diese vorkommt (oder auch nicht), denn die technischen Lösungen – Checksummen oder Erasure Coding – erschlagen dieses Problem immer gleich mit.
bcachefs ist einer von mehreren Kandidaten. Es ist mir persönlich aber noch zu neu. Einige der versprochenen Features (z.B. Snapshots) sind noch gar nicht fertig, andere (z.B. Verschlüsselung) stuft der Autor selbst als zu wenig getestet ein. Eigentlich sollte das On-Disk Format seit Mitte 2018 fest sein, im letzten Changelog von Ende 2018 steht aber klar, dass es noch weitere Änderungen geben wird. Bevor das On-Disk Format nicht stabil ist, riskiert man, ein Dateisystem später konvertieren oder sogar noch mal umkopieren zu müssen. Auch sehe ich nicht, dass “die Community” auf bcachefs setzt. Im Kern steht dahinter genau ein Entwickler, der Code wurde immer noch nicht in den Linux-Kernel aufgenommen, keine bekanntere Distribution unterstützt es. Sprich es vergehen mindestens noch mal fünf Jahre bis man damit rechnen kann, ein bcachefs-Dateisystem auf den meisten GNU/Linux-Systemen erzeugen oder mounten zu können.
BTRFS galt auch schon mal als total stabil und klarer Favorit für alles, dann tauchte plötzlich der kritische Fehler im RAID5/6-Code auf. Es gab auch schon Ideen für eine Lösung dieses Problems. Dass endlich jemand aufsteht, diese umsetzt und BTRFS doch noch dominiert ist mindestens genau so wahrscheinlich wie dass sich einer der neueren Konkurrenten durchsetzt. Aber BTRFS kann man halt Stand heute auf so gut wie jedem System mit vollem Funktionsumfang nutzen. Die anderen nicht.
Klasse Beitrag! Kenne ZFS seit ca. 2007, setze es auf verschiedenen Speichersystemen ein. Privat habe ich BTRFS auf Synology. Leider liegt bei Synology das BTRFS auf dem hauseigenen RAID von Synology an. Fehlererkennung zwar möglich, aber Fehlerbehebung ggf. nur über zusätzliche Redundanz. OpenZFS gibt es für offene Solaris Versionen, BSD Versionen, Linux und in Ubuntu bald im Kernel, macOS (OpenZFS Download). Schön, dass die Pools/Daten portabel sind, sofern das Ziel einen gleichen oder neueren ZFS Stand hat. Es geht bei ZFS so weit, dass sogar die Controller Hardware oder Anschlusstechnik frei wählbar bleibt. Das System kann so sicher in die Zukunft portiert werden.
Schade nur, dass man solche Beiträge eher im Web suchen muss, Danke dafür!
Hier nochmal ein gutes Video leider in englisch!
https://www.youtube.com/watch?v=rx10tWMhxrw
Pingback: How to configure the ZFS in an Ubuntu installation to get a RaidZ1 and its data security even with only one hard disk? - SharewareDepo.com - Latest Web Hosting News ()
NerdZoom Media | Impressum & Datenschutz